Notes for VE477 (Introduction to Algorithms) | FA2020 @UM-SJTU JI, Shanghai Jiao Tong University.
Computational Problem
- a computational problem is a question or a set of questions that a computer might be able to solve. (what is a computer?)
- study of the solutions to the computational problem composes the field of Algorithms
- computational complexity attempts to classify the algorithm depending on their speed or memory usage.
- decision problem
- search problem
- counting problem
- optimization problem
- function problem
Turing Machine
- a function is said to be Turing computable if there exists a Turing machine which returns for any input .
- deterministic polynomial algorithm:
- a language, decision problem
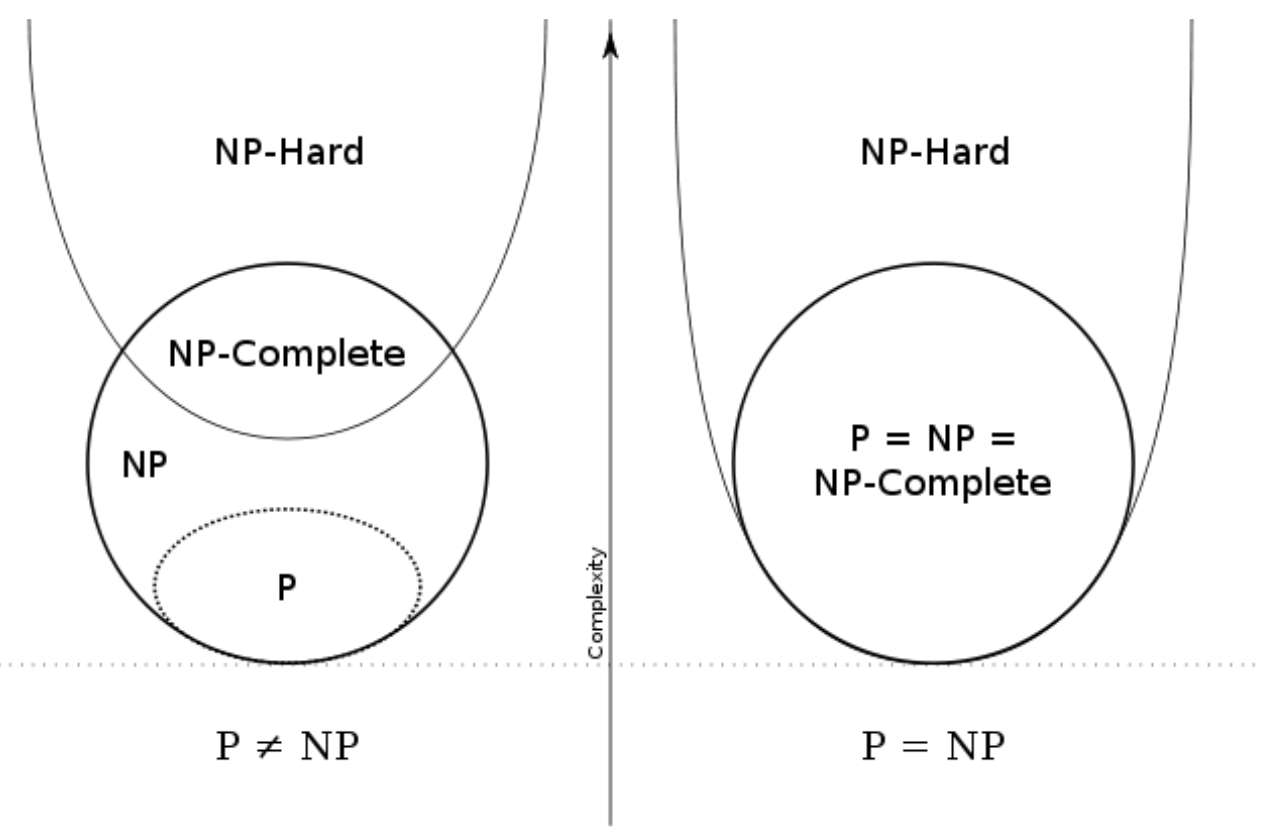
- The set of the decision problems which could be solved by a deterministic polynomial algorithm defines the class P.
- class NP: a decision problem is computable by a non-deterministic polynomial algorithm.
- be polynomial with the certificate
- class co-NP
- NP-Complete: NP-Complete is a complexity class which represents the set of all problems
Xin NP for which it is possible to reduce any other NP problemYtoXin polynomial time. - NP-hard: do not have to be in NP, do not have to be decision problem. a problem
Xis NP-hard, if there is an NP-complete problemY, such thatYis reducible toXin polynomial time.
P问题是在多项式时间内可以被解决的问题,而NP问题是在多项式时间内可以被验证其正确性的问题。 NP困难问题是计算复杂性理论中最重要的复杂性类之一。如果所有NP问题都可以多项式时间归约到某个问题,则称该问题为NP困难。
contains all problems in
-
PSPACE completeness
SPACE: denote the set of all the decision problems which can be solved by a Turing machien in space for some function of the input size . PSPACE is defined as
PSPACE-complete: 1. in PSPACE 2. for all in PSPACE, can be reduced in polynomial space the to
halting problem: undecidable. Do not belong to . . reduce SAT to Halting problem
-
SAT
boolean satisfiability problem: NP-complete
-
TQBF: PSPACE-complete and NP-hard
True Quantiffied Boolean Formula: can be solved in exponential time and polynomial space.
- when quantifier , the both should be evaluted true
- , only one of them
Then each time recursive call will give at most 2 way, then
-
Hilbert’s tenth problem
Given a Diophantine equation, with any number of unkown quantities and with rational integral numerical coefficients, decide whether the equation is solvable in rational numbers (decision problem).
-
3-SAT
example of how to proceed to evaluate the complexity class of a given problem
cnf: conjunctive normal form: if a boolean formula is written as the conjunction of disjunctive clauses.
3-SAT is NP-complete:
-
3-SAT is in (clearly as it is a particular case of SAT)
-
in that being able to solve it means being able to solve SAT, the proposed transformation is applicable in polynomial time
Convert a cnf-formula to a 3cnf-formula (then could transform any instance of SAT into an instance of 3-SAT)
Denote each clause in as
a. For clause has one literal as , change to
b. For clause has two literals as , change to
c. For clause has more than three literals as , introduce new variable change toan example:

Then we could rewrite it as
$$
\begin{align*}
&(x_1\lor x_2 \lor z_1)\land (\neg z_1\lor \neg x_3 \lor z_2)\land (\neg z_2\lor x_4 \lor z_3)\land (\neg z_3\lor x_5 \lor\neg x_6)\land \
&(\neg x_1\lor \neg x_2 \lor z_1)\land (\neg z_1\lor x_3 \lor z_2)\land (\neg z_2\lor\neg x_4 \lor z_3)\land (\neg z_3\lor x_5 \lor x_6)\land \
&( x_1\lor \neg x_2 \lor z_1)\land (\neg z_1\lor \neg x_3 \lor z_2)\land (\neg z_2\lor x_4 \lor z_3)\land (\neg z_3\lor x_5 \lor \neg x_6)\land \
&(x_1 \lor \neg x_2 \lor x_1)
\end{align*}
-
- stirling’s formula

1+2+4+8+…+2^{log n} 2n-1. Thus, the time complexity is .
Running time is expressed as T(n) for some function T on input size n.
also
complexity theory
-
RAM model

The complexity of an algorithm is defined by a numerical function

A sufficient condition of Big-Oh


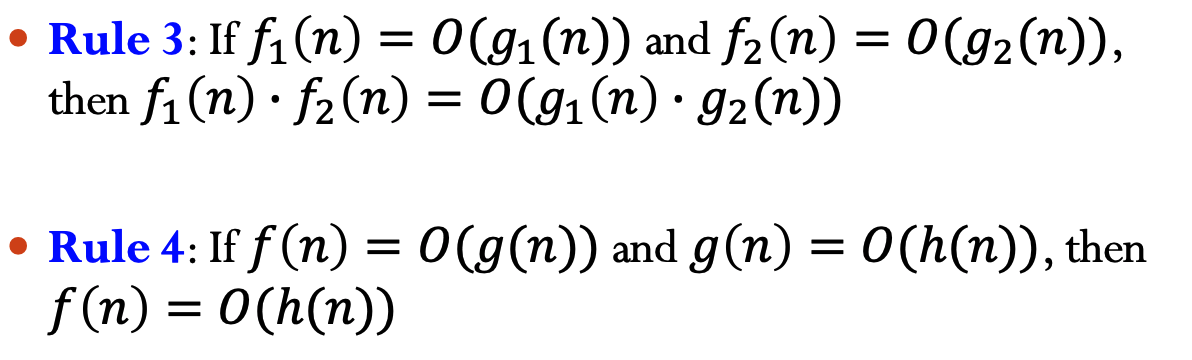
?



Solve Recurrence
Master method:
- base case: for sufficiently small ,
- a = number of recursive calls (positive integer)
- b = input size shrinking factor (positive integer)
- : the runtime of merging solutions. d is a real value $\geq $ 0
- a, b, d : independent of n

- In merge sort, a=2, b=2, d=1
- in quick sort, if choose the median as the pivot, a=2,b=2,d=1
- in binary search, a=1, b=2, d=0
Divide-and-conquer Approach
- merge sort
- Quick sort
Counting inversions
- divide into 2 sets
- in each set, recursively count the number of inversions
- sort each sort
- when merge, as need to compre the number, could get the number
Sorting
A sorting algorithm that is based on pairwise comparisons mush use operations to sort in the worst case
Reorder array A of size N with consistent comparison function
-
in place: requires additional memory;不占用额外内存,只利用原来存储待排数据的存储空间进行比较和交换。
“ Space usage affects the constant factor, because the memory access takes time. Modern computers are based on memory hierarchy. The top is small cache, but extremely fast. If O(1) additional space, it can be fit inside the cache and then, the program is fast; otherwise, it cannot be fit inside the cache, which needs to read the secondary memory, which takes time. ”
-
Stability: whether the algorithm maintains the relative order of records with equal keys
| Best Case Time | Worst Case Time | Average Case Time | In Place | Stable | |
|---|---|---|---|---|---|
| Insertion | O(N) sorted array | O() 逆序array | O() | Yes | Yes |
| Selection | О(n2) comparisons, O(1) Swap | O() | O() | Yes | No |
| Bubble | O() | O() | Yes | Yes | |
| Merge Sort | O() | O() | No | Yes | |
| Quick Sort | O() | O() | Weakly | No |
Comparison Sort
Each item is compared against others to determine its order
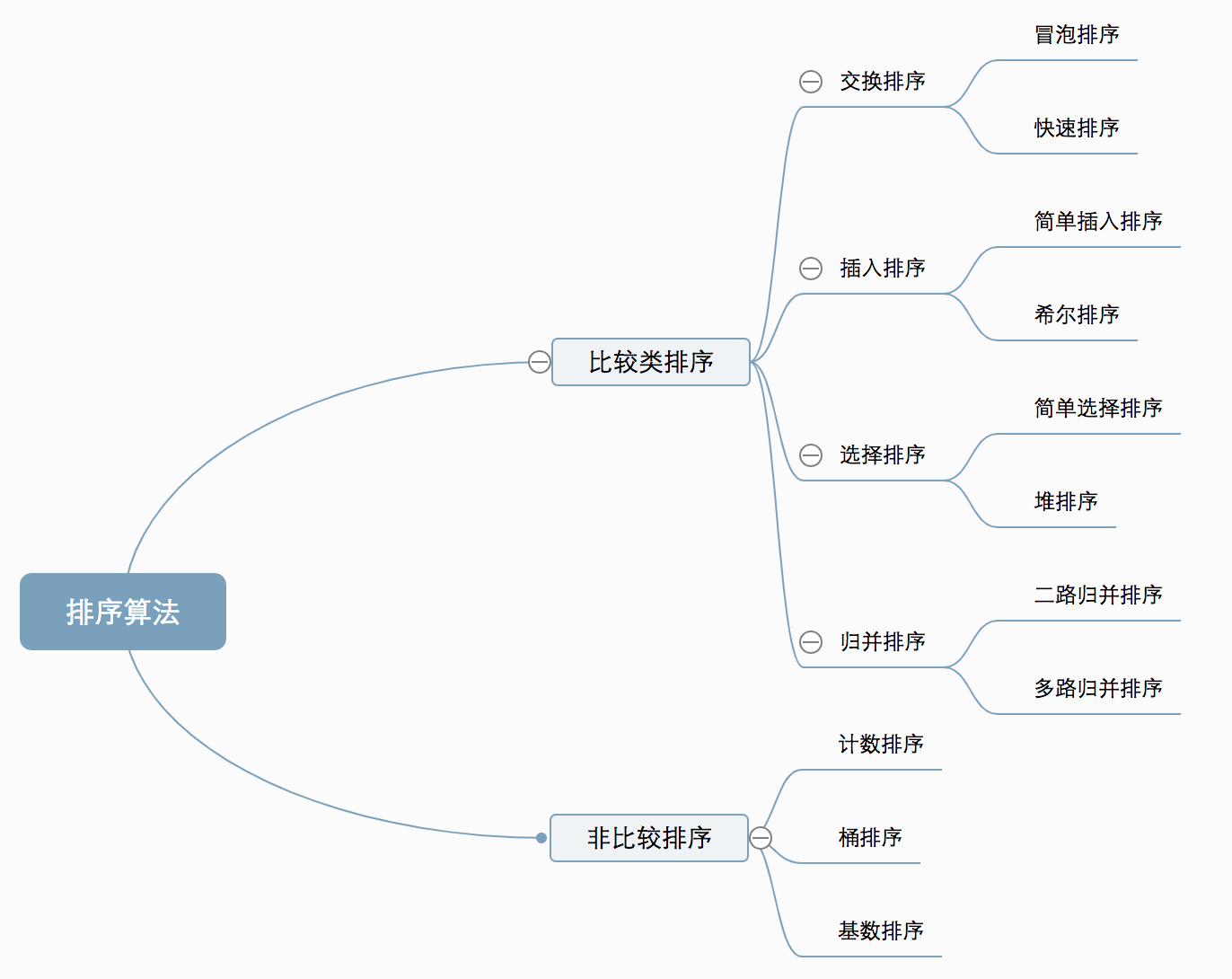
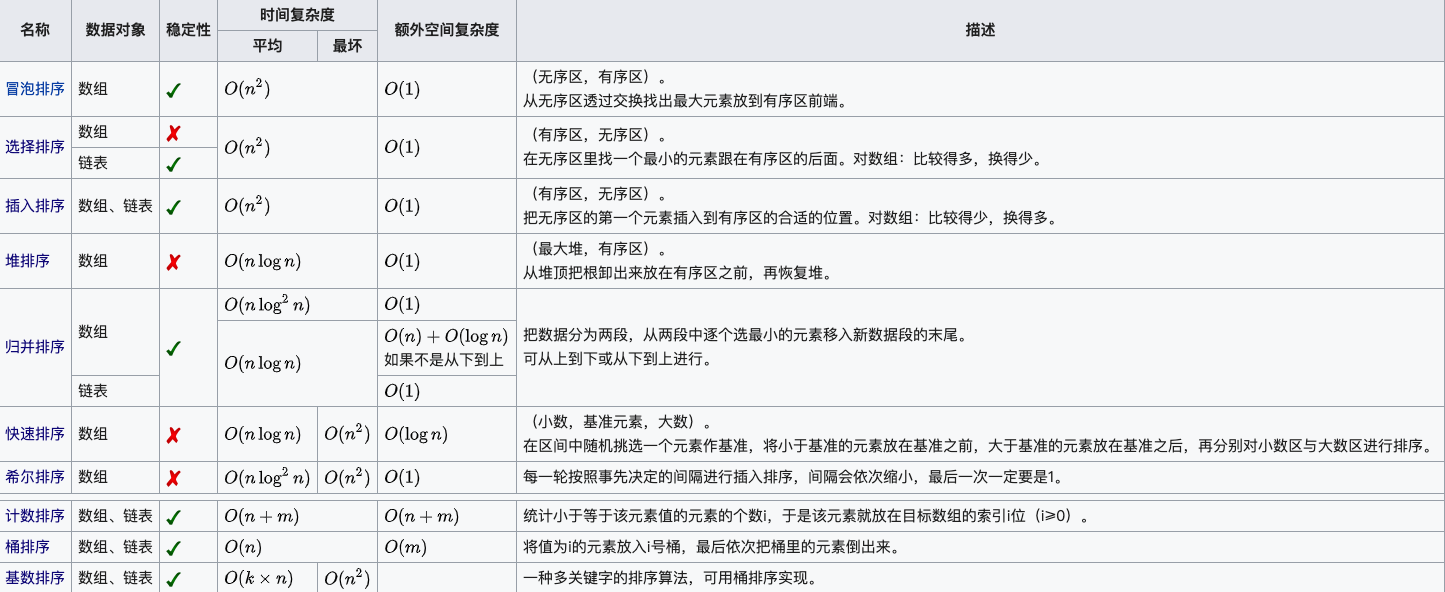
Simple sorts
- insertion sort
- selection sort
- bubble sort
Fast sort: quick sort and merge
Quick Sort
select a pivot randomly
- worst case : 每次都选到了最大/最小的元素
出现可能 - extremely samll

- On average

how to do partition? Not in place: with another array B
in-place partition
1. once select a pivot, swap the pivot with the first element in the array
2. set two pointer i,j; i points to the second element in the array, i = 1; j points to the last elemtn j = N - 1
3. Then increment i until find A[i] >= pivot
4. decrease j until find A[j] < pivot
5. if i < j : swap A[i] and A[j] the go back to 3.
6. otherwise swap the first element (the pivot) with A[j]
Non-comparison Sort / distribution-based sort
- each item is put into predifined “bins”, independent of other items; no comparison with other items needed
- Counting sort / bucket sort / radix sort
Counting sort
Assume that the input consists of data in a small range
给定array,已知其中data range为(0,k) + length of the array N (k and N are both parameters, although known, not treated as constant)
- allocate a new array with size k+1
- store the number of each number in the original array in
- Sum all number from to in as
- from the end of , put each element in in the new array at the position , then $count[A[n]] -=1 $

Bucket sort
Assume that the input is drawn from a uniform distribution, then linear time complexity could be obtained. (the time complecity is relevant to the input)
- set an array as an initially empty bucket
- Go over the array, put each item into corresponding bucket
- in each bucket, do comparison sort
- visit all the buckets in order and put all items back to the original array

Radix sort
比如sort name, 因为姓氏的集中性,not good for it
each element in the n-element array has digits, where digit 1 is the lowest-order digit and digit is the highest order.

In-place and not in-place both merge sort each subarray recursively, the difference is in the merge function. For the marge sort discussed in the class, $$\leq $$ is used to compare so that it is stable.
In-place merge sort need to shift all the element because no additional memory (like the additional array in slides), so time complexity $$O(n^2)$$ not $$O(nlogn)$$ any more.
LinearTime Selection
Randomized selection algorithm

Average :
Input array size n && random pivot choice
Rselect is in phase j: current array size is between and .
: the number of recursive calls in phase
For example, phase 0 is size between [3/4n, n]. Depends on what the pivot you choose, the array may enter a new phase or remain in the current phase
Good pivot: make the left sub-array size is am, i.e. 1\4<a<3\4. Probability: 0.5. 因为只要在old array中间50%的位置取即可获得

E[]≤ Expected number of times you need to get a good pivot, p=0.5, == flip coin
小于:因为即使无good pivot也可能进入new phase
N: the number of chosen needed to get a good pivot. P[N=k] = ; E[N]=2.
E[] <= E[N] = 2

第一层循环中将pivot与n个元素进行比较,时间为.: 第一步时间
相似的,在递归过程中
则有
空间复杂度:无额外的空间,inplace
The runtime depends on the input pivot
When i = n/2 ,the worst case runtime is , such that example array 1,2,3,4,5,6,7, choose pivot sequence 1,2,3,7,6,5,4 then comparison time: c(n-1 + n-2 + … + n/2 + … 1). However, if choose 1,2,3,4,5,6,7, only c(n-1 + n-2 + … + n/2 )
Best:
Best case happens when your random selection of pivot directly gives you the i-th smallest item (i.e., a pivot with index as i). However, the pivot index can only be known after the partition. Thus, the runtime is .
Deterministic selection algorithm
Idea: use “median of medians”
ChoosePivot(A, n)
-
A subroutine called by the deterministic selection algorithm
-
Steps
1.Break A into n/5 groups of size 5 each
2.Sort each group (e.g., use insertion sort)
3.Copy n/5 medians into new array C
4.Recursively compute median of C
By calling the deterministic selection algorithm!
5.Return the median of C as pivot
Dselect

Intpu array size n; Runs on time
but not in-place: need an additional array of 5/n medians
-
对于长度为5的array排序,时间为constant,
-
why size <= 0.7n
-

于是可以看出在图中T(?)处的size不会大于0.7n
因此对于整个dselect来说,
Hope: there is a constant a (independent of n) such that T(n)≤an for all n>1
Then T(n)=O(n)
We choose a=10c, so to prove ->
Proof by induction:
-
base case:
-
inductive step: inductive hypothesis
Then prove it also true for :
Dynamic Programming
idea behind DP:
- break a complex problem into simpler subproblems
- store the result of the overlapping subproblems
- do not recompute the same information again and again
- do not waste memory because of recursion
saves both time and space
- simple idea dramatically improving space-time complexity
- cover all the possibilities at the subproblem level
- efficient as long as the number of subproblems remains polynomial
eg: fibnonacci number naive way: do recursion
- Memorized DP: recursion + memorization
**time = #of sub problems time/subproblem **
mem={}
fib(n):
if n in mem: return mem[n]
else:
if n <= 2: f = 1
else: f = fib(n-1) + fib(n-2)
mem[n] = f
return f
// # of subproblem:n & time/subproblem is \Theta(1)
- fib(k) only recurses when it is first called
- only n nonmemorized calls: k=n, n-1, … 1
- memorized call free ( time)
- could ignore recursion, time per call
https://www.zhihu.com/question/23995189
-
Bottom-up DP
fib = {} for k in [1,2, ...,n]: # n loops, each call is \Theta(1) if k <= 2: f = 1 else: f = fib(n-1) + fib(n-2) fib[k] = f return fib[n] // same computation as do not need to count for recursion but save space
intro
用尽量少的1,5,11凑出15;贪心策略, 五张。
正确的为, 三张。 贪心策略为尽量使之后面对的w更少,只考虑眼前情况
用 表示凑出n所需要的最少数量。与1,5,11各用了多少无关。
Cost = f(4) + 11 / f(10) + 5 / f(14) + 1 -> $f(n) = min{ f(n-1),f(n-5),f(n-11)} + 1 $
以 复杂度解决
-
将一个问题拆成几个子问题,分别求解这些子问题,即可推断出大问题的解
-
Definitions: (DP 需要满足的前提)
- 无后效性:确定f(n)后,如何凑出f(n)即无关
- 最优子结构: f(n)即为小问题的最优解, 因此可以得出大问题的最优解
DP: 枚举有可能成为答案的解,自带剪枝 - 尽量缩小可能解空间
knapsack problem
subset sum problem
time complexity
- Use a boolean subset[i][j] to denote if there is a subset of sum j with element at index as the last element.
subset size: (A.size() + 1) * (target + 1)
subset[i][j] = True
## sum of a subset with the i-1 th element as the last element, equal to j
if (A[i] > j)
subset[i][j] = subset[i - 1][j] // copy the answer for previous cases
else
subset[i][j] = subset[i - 1][j] OR subset[i - 1][sum - A[i]]
// if any previous states have already experinced the sum=j OR
// OR any previous state experinced a value 'j - A[i]'
Shortest path
Implementation: dij & bellmanford in VE477 lab5 (lab4: fib heap)
shortest path in weighted graph: Given a connected, simple, weighted graph, and two vertices and , find the shortest path that joins to .
- Egdes only have positive weights
- Edges have positive and negative egdes
- Dijkastrs’s algorithm: only for solving the case 1, could not deal with negative weights. (no DP involved)
- Bellman-Ford: take advantage of DP
Subproblem dependency should be acyclic
String
when subproblem for strings: (all polynomial)
- Suffixes
- prefixes
- substrings
-
Edit Distance:
given two string and , the cheapest possible sequence of character edits to turn .
ALLOW:
- Insert
- Delete
- replace with
SUBPROBLEM: then
GUESS: one of three allowed possibilities
RECURRENCE: DP(i, j) = min{ (cost of repalce x[i]->y[j] + DP(i+1, j+1) , cost of insert y[j] + DP(i, j+1), cost of delete x[i] + DP(i+1, j)}
TOPO ORDER: i: |x| -> 0
j: |y| ->0
DP(\emptyset, \O)
Time comlexity: subproblem . Total:
longest common sequence: for these two words
Union-Find
A disjoint-set data structure is a data structure that keeps track of a set of elements partitioned into a number of disjoint (non-overlapping) subsets. A union-find algorithm is an algorithm that performs two useful operations on such a data structure:
并查集是一种树型的数据结构,用于处理一些不交集的合并及查询问题; 不能将在同一组的元素拆开
two operations
Find(v): find the root of the tree for vertexUnion(v, w): link the root of the tree containg vertex to the root of tree containing vertex
两处优化
- When
Find, update all the nodes along the path (all link them to the root directly) - When
Union, set the root with higher depth as the parent of another root (minimize the depth of the tree)

Complexity
-
Lemma

-
iterated logarithm function

such that, the iterated algorithm of n is the number of time that the function log need to be applied to obtain a number smaller than 2
-
The cost for one
findoperation isbecause for each
find, the path will be compressed, -
The amortized time for a sequence of
GenSetUnionFindoperations, of which areGenSetcan be performed in time .
The complexity of Union-Find structure is
Ackerman’s function
inverse Ackerman’s function
MST
Implement: VE477 lab2 (Minimum Spnning Tree)
- Definitions
- tree: acyclic, connected undirected graph;
- any connected graph with nodes and edges is a tree
- graph , subgraph iff
- spanning tree of a connected undirected graph is a subgraph of that contains all the nodes and is a tree.
- weighted, connected and undirected graph -> MST, which is a spanning tree with the minimum sum of weights.
- is a tree: if it contained a cycle, at least one edge could be removed, allowing a lower weight while preserving the connected property of
-
Algorithms
a. Prim’s Algorithm
-
, nodes added to MST; nodes not in MST
-
For each node , keep a measure storing current smallest weight over all edges that connect to a node in
-
Keep for each node : is the edge chosen in MST
Full version:
-
Pick one node , set , for any other node , set and unknown
-
Set
-
While $T’ \neq \emptyset $
- For all nodes in , choose a node that has the smallest .
- Remove from set
- For neighbors that still in , if exist , then update as and as
b. Kruskal’s Algorithm
Greedy Algorithm, union-find data structure
- sort all the edges by weight
- for edges in in non-decreasing order, adding them into if no cycle would be created
To check whether a cycle will be created, union find: whether two edges have the same root
Find; add them:Union -
Network flow
网络流问题

- 对flow的限制:容量限制和流量守恒
- Antiparallel:
- multiple source and/or sink nodes: super node
Maximum Network Flow Problem
-
Residual graph . () 残存图

-
Argumenting path 增广路径. Residual capacity: on an argumenting path , the maximum flow that could be added to each edge s. 将沿着增广路径重复增加路径上的流量直到找到一个最大流. How to know we find a maximum flow? A flow is the maximum flow if and only if no argumenting path in the residual networks.
-
cuts of flow networks: One cut of flow network , cut the as .
If is a flow, then the net flow across the cut is defined to be
The capacity of a cut is: .
-
Minimum cut: A minimum cut of a network is a cut whose capacity is minimum over all cuts of the network.
Max-flow Min-cun Theorem
Algo. Examples
counting inversions
of low implement: VE477 lab3.1.1
数逆序对 application: voting theory / analysis of search engines ranking / collaborative filtering
Divide and conquer approach 将list分为两半,recursively sort list并记录count (sort and count). 接着将两个list (merge and count)
Algorithm. (Merge and count)
Input : Two sorted lists: L1 = (l1,1,··· ,l1,n1), L2 = (l2,1,··· ,l2,n2)
OutpuT: Number of inversions count, and L1 and L2 merged into L
Function MergeCount(L1 , L2 ):
count ← 0; L ← ∅; i ← 1; j ← 1;
while i≤n1 andj≤n2 do
if l1,i ≤ l2,j then
append l1,i to L; i++;
else
append l2,j to L; count←count + n1 − i + 1; j++; end if
end while
if i > n1 then append l2,j,··· ,l2,n2 to L;
else append l1,i,··· ,l1,n1 to counL;
return count and L
end
Algorithm. (Sort and count)
Input : A list L = (l1,··· ,ln)
Output : The number of inversions count and L sorted
Function SortCount(L):
if n=1 then return 0 and L;
else
Split L into L1 = (l1,··· ,l⌈n/2⌉) and L2 = (l⌈n/2⌉+1,··· ,ln);
count1, L1 ← SortCount(L1);
count2, L2 ← SortCount(L2);
count, L ←MergeCount(L1, L2);
end if
count ← count1 + count2 + count;
return count and L
end
time complexity: For merge O(n)
sort part: every time spilt it into two equal parts, a=2, b=2, f(n) = O(n),
So total for Sort and Count is
Stable Marriage Problem
Algorithm: Gale-Shapley
Implements 477 Lab3.1.2
Time complexity
N Queens Puzzle
Implementation: Leetcode #52
8*8棋盘上,皇后可以横直斜走,格数不限。皇后之间不可以相互攻击->任何两个皇后不可以在同一行,同一列以及同一斜线上。
backtracking:

Data Structure
A bit comparison of different data structure.
Array has better memory locality and cache performance, arrays are contiguous memory blocks, so large chunks of them will be loaded into the cache upon first access.
| Dictionary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Array (Unsorted/Sorted) | |||||||||
search(D,k) |
|||||||||
insert(D,k) |
|||||||||
delete(D,k) |
|||||||||
predecessor(D,k) |
|||||||||
successor(D,k) |
|||||||||
minimum(D) |
|||||||||
maximum(D) |
Dictionary using array

Dictionary using linked structure
Hashing
Basics
- Setup: a universe of objects (eg. all names, .., very big)
- Goal: maintain an evovling set (eg. 100 names, … ,reasonable size)
- original solution: array based / linked list based
Better solution
- Hash table, an array A of n buckets
- hashing function
- store item in A[h(k)]
Collision: item with differnet search keys hashed into the same buckets (to solve: seperate chaining / open addressing)
Hash Function Design Criteria:
